
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- CTF
- 역전파
- 리뷰
- Python Challenge
- AdaGrad
- PICO CTF
- 오차역전파법
- HTML
- C언어
- 아파치
- 신경망
- 백준
- 설치
- FastAPI
- 신경망 학습
- 책
- 우분투
- 딥러닝
- 소프트맥스 함수
- sgd
- 코딩
- flag
- PHP
- 파이썬
- Apache2
- PostgreSQL
- 기울기
- 순전파
- picoCTF
- Python
- Today
- Total
Story of CowHacker
딥러닝 2.9 신경망 본문
이번 글에서는 배치 처리에 대해 알아볼 것이다.
import sys, os
sys.path.append(os.pardir) # 부모 디렉터리의 파일을 가져올 수 있도록 설정
import numpy as num
import pickle
from dataset.mnist import load_mnist
from common.functions import sigmoid, softmax
def get_data():
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, flatten=True, one_hot_label=False)
return x_test, t_test
def init_network():
with open("sample_weight.pkl", 'rb') as f:
network = pickle.load(f)
return network
def predict(network, x):
W1, W2, W3 = network['W1'], network['W2'], network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3']
a1 = num.dot(x, W1) + b1
z1 = sigmoid(a1)
a2 = num.dot(z1, W2) + b2
z2 = sigmoid(a2)
a3 = num.dot(z2, W3) + b3
y = softmax(a3)
return y
x, _ = get_data()
network = init_network()
W1, W2, W3 = network [ 'W1' ], network [ 'W2' ], network [ 'W3' ]
print ( x.shape )
print ( x [ 0 ].shape )
print ( W1.shape )
print ( W2.shape )
print ( W3.shape )
배치 처리를 알아보기 전 앞 글에서 구현한 신경망 각 층의 가중치 형상을 출력해봤다.
결과를 보면 다차원 배열의 대응하는 차원의 원소 수가 일치함을 확인할 수 있다.
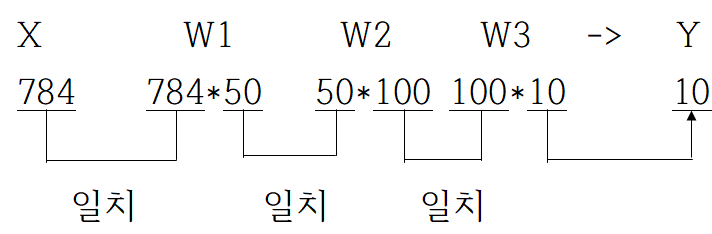
그림1은 위 코드를 식으로 나타낸 것이다.
원소 784개로 구성된 1차원 배열이 입력되어 마지막에는 원소가 10개인 1차원 배열이 출력되는 순서다.
이것은 데이터를 1장만 입력했을 때의 처리 순서다.
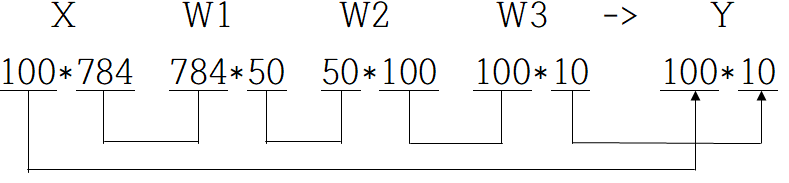
그림2는 1장이 아닌 100장의 이미지를 처리하는 순서다.
이처럼 하나로 묶은 입력 데이터를 배치라고 한다.
이제 배치 처리를 파이썬으로 구현해보겠다.
import sys, os
sys.path.append(os.pardir)
import numpy as num
import pickle
from dataset.mnist import load_mnist
from common.functions import sigmoid, softmax
def get_data():
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, flatten=True, one_hot_label=False)
return x_test, t_test
def init_network():
with open("sample_weight.pkl", 'rb') as f:
network = pickle.load(f)
return network
def predict(network, x):
W1, W2, W3 = network['W1'], network['W2'], network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3']
a1 = num.dot(x, W1) + b1
z1 = sigmoid(a1)
a2 = num.dot(z1, W2) + b2
z2 = sigmoid(a2)
a3 = num.dot(z2, W3) + b3
y = softmax(a3)
return y
x, t = get_data()
network = init_network()
batch_size = 100
accuracy_cnt = 0
for _ in range ( 0, len ( x ), batch_size ):
x_batch = x [ _ : _ + batch_size ]
y_batch = predict ( network, x_batch )
p = num.argmax ( y_batch, axis = 1 )
accuracy_cnt += num.sum ( p == t [ _ : _ + batch_size ] )
print ( " Accuracy : " + str ( float ( accuracy_cnt ) / len ( x ) ) )
코드 해석을 해보면 range 함수가 반환하는 리스트를 방탕으로 x [ _ : _ + batch_size ] 에서 입력 데이터를 묶는다.
x [ _ : _ + batch_size ]은 입력 데이터의 _번째부터 _ + batch_size 번째까지의 데이터를 묶는다는 뜻이다.
이 예에서는 batch_size 가 100이므로 x [ 0 : 100 ], x [ 100 : 200 ],... 와 같이 앞에서부터 100장씩 묶는다.
그리고 argmax 함수는 최댓값의 인덱스를 가져온다.
다만 여기서는 axis = 1이라는 인수를 추가한 것에 주의한다.
이는 100 * 10의 배열 중 1 번째 차원을 구성하는 각 원소에서 최댓값의 인덱스를 찾도록 한 것이다.
자세히 들어가 range 함수와 argmax함수를 따로 파이썬으로 구현해보겠다.
range 함수는 인수를 2개 ( range ( strat, end ) ) 지정해 호출하면 start에서 end-1까지의 정수로 이뤄진 리스트를 반환한다.
만약 range ( strat, end, step ) 처럼 인수를 3개 지정하면 start에서 end-1까지 step간격으로 증가하는 리스트를 반환한다.
무슨 소린지 파이썬으로 구현해보자.
x, t = get_data()
network = init_network()
batch_size = 100
accuracy_cnt = 0
for _ in range ( 0, len ( x ), batch_size ):
x_batch = x [ _ : _ + batch_size ]
y_batch = predict ( network, x_batch )
p = num.argmax ( y_batch, axis = 1 )
accuracy_cnt += num.sum ( p == t [ _ : _ + batch_size ] )
print ( list ( range ( 0, 10 ) ) )
print ( list ( range ( 0, 10, 3 ) ) )
위 코드로 range 함수의 원리를 확인할 수 있다.
다음은 argmax함수를 한번 확인해보자.
x, t = get_data()
network = init_network()
batch_size = 100
accuracy_cnt = 0
for _ in range ( 0, len ( x ), batch_size ):
x_batch = x [ _ : _ + batch_size ]
y_batch = predict ( network, x_batch )
p = num.argmax ( y_batch, axis = 1 )
accuracy_cnt += num.sum ( p == t [ _ : _ + batch_size ] )
x = num.array ( [ [ 0.1, 0.8, 0.1 ], [ 0.3, 0.1, 0.6 ], [ 0.2, 0.5, 0.3 ], [ 0.8, 0.1, 0.1 ] ] )
y = num.argmax ( x, axis = 1 )
print ( y )
이제 배치 단위로 분류한 결과를 실제 답과 비교해보는 걸 확인해보겠다.
x, t = get_data()
network = init_network()
batch_size = 100
accuracy_cnt = 0
for _ in range ( 0, len ( x ), batch_size ):
x_batch = x [ _ : _ + batch_size ]
y_batch = predict ( network, x_batch )
p = num.argmax ( y_batch, axis = 1 )
accuracy_cnt += num.sum ( p == t [ _ : _ + batch_size ] )
y = num.array ( [ 1, 2, 1, 0 ] )
t = num.array ( [ 1, 2, 0, 0 ] )
print ( y == t )
print ( num.sum ( y == t ) )
위 코드는 배치 단위로 분류한 결과를 실제 답과 비교하기 위해 == 연산자를 사용해 넘 파이 배열끼리 비교하여 True / False로 구성된 bool 배열을 만들고, 이 결과 배열에서 True가 몇 개인지 세는 구조다.
정리
이로써 신경망의 순 전파 ( 추론 과정 ) 에 대해 알아봤다.
신경망과 퍼셉트론은 뉴런들이 다음 층의 뉴런으로 신호를 전달한다는 점에서 공통점을 가진다.
차이점은 다음 뉴런으로 갈 때 신호를 변화시키는 활성화 함수에 큰 차이가 있다.
신경망은 시그모이드 함수를, 퍼셉트론은 계단 함수를 활성화 함수로 사용했다는 것이다.
이 차이가 신경망 학습에서 중요점이다.
이까지 배운 내용
1. 신경망에서는 활성화 함수로 시그모이드 함수와 ReLU 함수 같은 매끄럽게 변화하는 함수를 이용한다.
2. 파이썬내에 넘파이의 다차원 배열을 잘 사용하면 신경망을 효율적으로 구현할 수 있다.
3. 머신러닝 문제는 크게 회귀와 분류로 나눌 수 있다.
4. 출력층의 활성화 함수로는 회귀에서는 주로 항등 함수를, 분류에서는 주로 소프트맥스 함수를 이용한다.
5. 분류에서는 출력층의 뉴런 수를 분류하려는 클래스 수와 같게 설정한다.
6. 입력 데이터를 묶은 것을 배치라 하며, 추론 처리를 이 배치 단위로 진행하면 결과를 훨씬 빠르게 얻을 수 있다.
'공부 > 딥러닝' 카테고리의 다른 글
| 딥러닝 3.1 신경망 학습 (0) | 2020.08.12 |
|---|---|
| 딥러닝 3.0 신경망 학습 (0) | 2020.08.11 |
| 딥러닝 2.8 신경망 (0) | 2020.08.08 |
| 딥러닝 2.7 신경망 (0) | 2020.08.06 |
| 딥러닝 2.6 신경망 (0) | 2020.08.05 |


